Notes on Stochastic Processes (Joe Chang)
Ch. 1 – Markov Chains
1.1 Specifying and Simulating a Markov Chain
to specify a Markov chain, we need to know its
- state space , a finite or countable set of states—values the random variables may take on
- initial distribution , the probability distribution of the Markov chain at time .
- for each state , , the probability the Markov chain starts in state we can also think of are a vector whose -th entry is
- probability transition matrix
- if has states, then is
- or is the probability that the chain will transition to from : .
- rows sum to 1 (think: from state , we are in row , and there must be probability 1 of going to any next state )
1.2 The Markov Property
a process satisfies the Markov property if
for all and all .
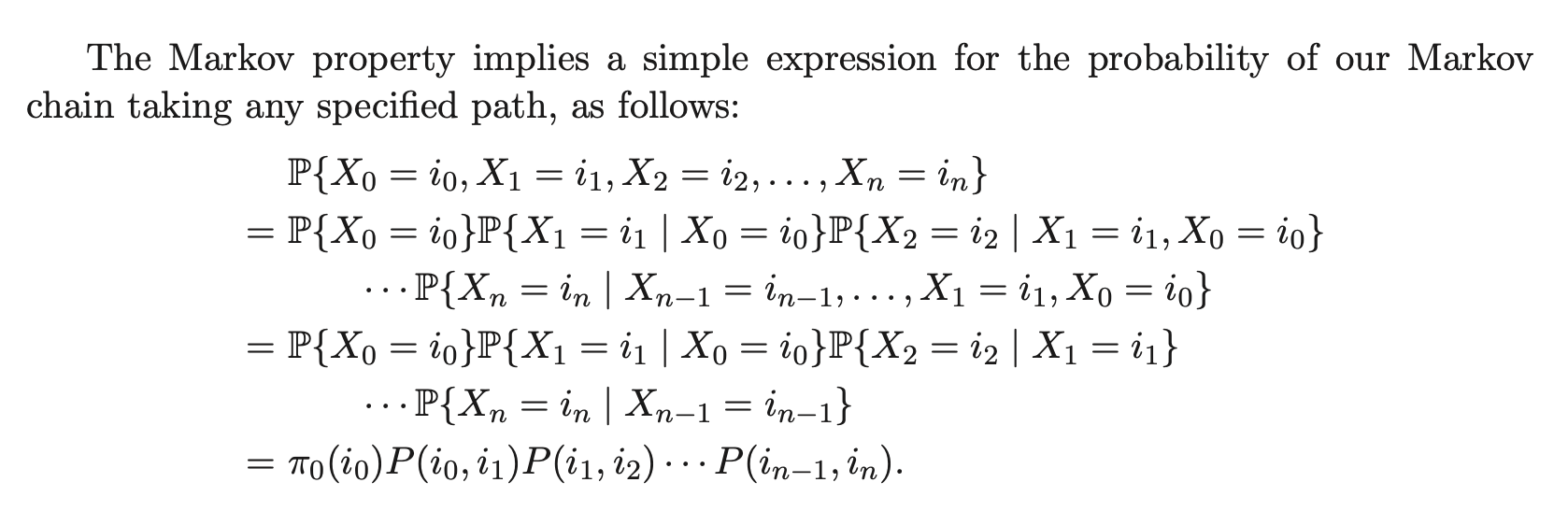
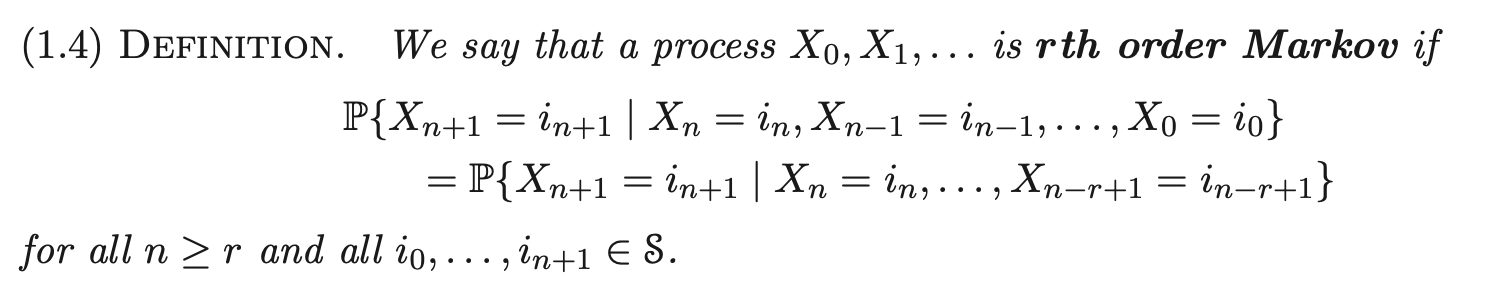
(i.e., dependent on the last r states)
1.3 Matrices
recall from 1.1. let denote the distribution of the chain at time analogously, . consider both as row vectors.
suppose that the state space is finite: . by LOTP,

1.4 Basic Limit Theorem of Markov Chains

1.5 Stationary Distribution
stationary distribution amounts to saying is satisfied, i.e.,
for all .
a Markov chain might have no stationary distribution, one stationary distribution, or infinitely many stationary distributions.
for subsets of the state space, define the probability flux from set into as
1.6 Irreducibility, Periodicity, Recurrence
Use as shorthand for , and same for .
Accessibility: for two states , we say that is accessible from if it is possible for the chain ever to visit state if the chain starts in state :
Equivalently,
Communication: we say communicates with if is accessible from and is accessible from .
Irreducibility: the Markov chain is irreducible if all pairs of states communicate.
The relation “communicates with” is an equivalence relation; hence, the states space can be partitioned into “communicating classes” or “classes.”
–
The Basic Limit Theorem requires irreducibility and aperiodicity (see 1.5). Trivial examples why:
- Irreducibility: takes . Then holds for all , i.e., does not approach a limit independent of .
- Aperiodicity: same , take . If, for example, alternates with even and odd , and does not converge to anything.
–
Period: Given a Markov chain , define the period of a state to be the greatest common divisor
THEOREM: if the states and communicate, then .
The period of a state is a “class property.” In particular, all states in an irreducible Markov chain have the same period. Thus, we can speak of the period of a Markov chain if the Markov chain is irreducible.
An irreducible Markov chain is aperiodic if its period is , and periodic otherwise. (A sufficient but not necessary condition for an irreducible chain to be aperiodic is that there exists a state such that .)
–
One more concept for the Basic Limit Theorem: recurrence. We will begin with showing recurrence, then showing that it is a class property. In particular, in an irreducible Markov chain, etiher all states are recurrent OR all states are transient.
The idea of recurrence: a state is recurrent if, starting from the state at time 0, the chain is sure to return to eventually. More precisely, define the first hitting time of the state i by
Recurrence: the state is recurrent if . If is not recurrent, it is called transient.
(note that accessibility could be defined: for distinct states , is accessible from iff .)
THEOREM: Let be a recurrent state, and suppose that is accessible from . Then all of the following hold:
- The state is recurrent
–
We use the notation for the total number of visits of the Markov chain to the sate :
THEOREM: The state is recurrent iff
COROLLARY: If is transient, then for all states .
–
Introducing stationary distributions.
PROP: Suppose a Markov chain has a stationary distribution . If the state is transient, then .
COROLLARY: If an irreducible Markov chain has a stationary distribution, then the chain is recurrent.
Note that the converse for the above is not true. There are irreducible, recurrent Markov chains that do not have stationary distributions. For example, the simple symmetric random walk on the integers in one dimension is irreducible and recurrent but does not have a stationary distribution. By recurrence we have , but also . The name for this kind of recurrence is null recurrence, i.e., a state is null recurrent if it is recurrent and . Otherwise, a recurrent state is positive recurrent, where .
Positive recurrence is also a class property: if a chain is irreducible, the chain is either transient, null recurrent, or positive recurrent. In fact, an irreducible chain has a stationary distribution iff it is positive recurrent.
1.7 Coupling
Example of coupling technique: consider a random graph on a given finite set of nodes, in which each pair of nodes is joined by an edge independently with probability . We could simulate a random graph as follows: for each pair of nodes generate a random number , and join nodes and with an edge if .
How do we show that the probability of the resulting graph being connected is nondecreasing in , i.e., show that for ,
We could try to find an explicit function for the probability in terms of , which seems inefficient. How to formalize the intuition that this seems obvious?
An idea: show that corresponding events are ordered, i.e., if then .
Let’s make 2 events by making 2 random graphs, on the same set of nodes. is constructed by having each possible edge appear with prob , and for , each edge present with prob We can do this by using two sets of random variables: for the first and second graph, respectively. Is it true that
No, since the two sets of r.v.s are independently generated.
A change: use the same random numbers for each graph. Then
becomes true. This establishes monotonicity of the probability being connected.
Conclusion: what characterizes a coupling argument? Generally, we show that the same set of random variables can be used to construct two different objects about which we want to make a probabilistic statement.
1.8 Proof of Basic Limit Theorem
The Basic Limit Theorem says that if an irreducible, aperiodic Markov chain has a stationary distribution , then for each initial distirbution , as we have for all states .
(Note the wording “a stationary distribution”: assuming BLT true implies that an irreducible and aperiodic Markov chain cannot have two different stationary distributions)
Equivalently, let’s define a distance between probability distributions, called “total variation distance:”
DEFINITION: Let and be two probability distributions on the set . Then the total variation distance is defined by
PROP.: The total variation distance may also be expressed in the alternative forms
We now introduce the coupling method. Let be a Markov chain with the same probability transition matrix as , but let have the initial distribution and have the initial distribution . Note that is a stationary Markov chain with distribution for all . Let the chain be independent of the chain.
We want to show that, for large , the probabilistic behavior of is close to that of .
Define the coupling time to be the first time at which :
LEMMA: For all n we have
Hence we need only show that , or equivalently, that
Consider the bivariate chain is clearly a Markov chain on the state space . Since the and chains are independent, the probability transition matrix of chain can be written
has stationary distribution
We want to show So, in terms of the chain, we want to show that with probability one, the chain hits the “diagonal” in in finite time. To do this, it is sufficient to show that the chain is irreducible and recurrent.